









この記事に関連するお役立ち資料

AIを活用した業務自動化 事例BOOK
無料ダウンロード
ChatGPTのような汎用AIを導入しただけでは、最新の情報や専門知識の不足、カスタマイズの難しさなど、様々な壁に直面します。「自社の特性に合わせたAIを構築したい」「より正確で信頼性の高い回答を得たい」といった悩みを抱える企業も少なくないでしょう。
そこで注目を集めているのが、RAG(Retrieval-Augmented Generation)と呼ばれる技術です。ただし、ChatGPTにRAGをくっつけて使う、という簡単なものではありません。
そこで本記事では、RAGの仕組みやChatGPTとの違い、導入のメリットについて詳しく解説します。さらに、実装時の重要ポイントや、ファインチューニングとの比較など、実践的な情報もお届けします。
RAGの導入で企業特有の課題に対応したAIシステムを構築できます。専門知識や最新情報を反映させた高精度な回答を実現しましょう。

- RAGってどのような技術?ChatGPTとの関係
- ChatGPTとRAGの違い
- Retrieval-Augmented Generationの仕組み
- ChatGPTだけの運用で直面する3つの課題
- 知識の更新頻度が低い
- 専門分野の深い知識が不足
- カスタマイズの難しさ
- そもそもChatGPTだとRAGは実行できない?
- ChatGPTのようなチャットボットの構築が基本
- RAG vs ファインチューニングはどっちがいい?
- コストと効果の観点
- データセキュリティとコンプライアンス
- どちらも使う方法も有効
- RAGを実装する際に知っておきたい3つのポイント
- データ品質の確保と更新を怠らない
- レスポンスタイムは最適化する
- ハルシネーションの対策を行う
- まとめ: RAGを導入するなら相談を
- よくある質問(FAQ)
- RAGを構築するにはいくら費用がかかる?
- RAGの欠点は何ですか?
- RAGはどのような業種や企業規模で効果的ですか?
- ▌【一緒に働くメンバー募集】生成AIを活用し、顧客の課題解決をしませんか?
RAGってどのような技術?ChatGPTとの関係
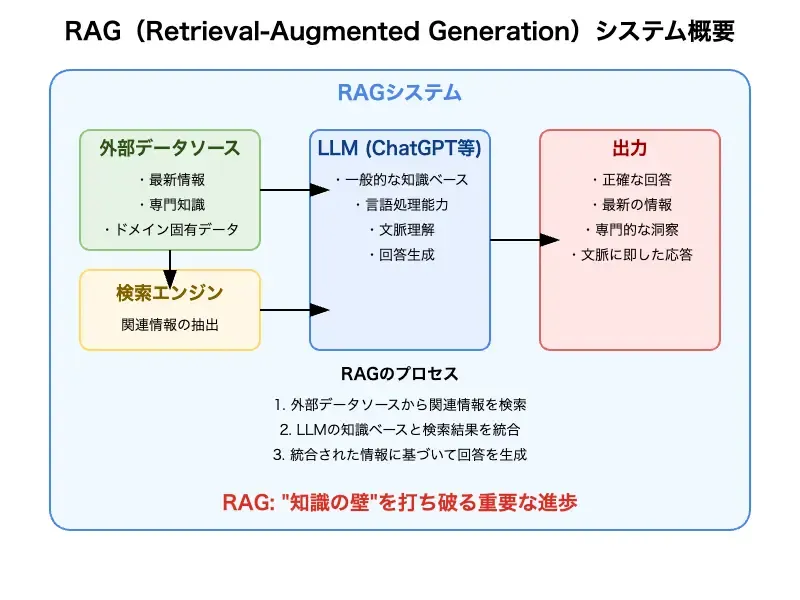
RAG(Retrieval-Augmented Generation)は、ChatGPTのような大規模言語モデル(LLM)の言語処理能力と、外部データソースからの情報検索を組み合わせることで、より正確で最新の情報を含む回答を生成することを可能にします。
RAGの基本的な考え方は、AIモデルが持つ一般的な知識ベースに、特定のドメインや最新の情報を追加することで、より適切で信頼性の高い出力を得ることです。
ChatGPTとRAGは密接な関係にあり、多くの場合、ChatGPTのようなLLMがRAGシステムの中核として機能します。AI技術の世界において、RAGは「知識の壁」を打ち破る重要な進歩として位置づけられています。
関連記事:RAGとは?文書生成AIの課題を軽減する技術のメリットわかりやすい活用イメージ
ChatGPTとRAGの違い
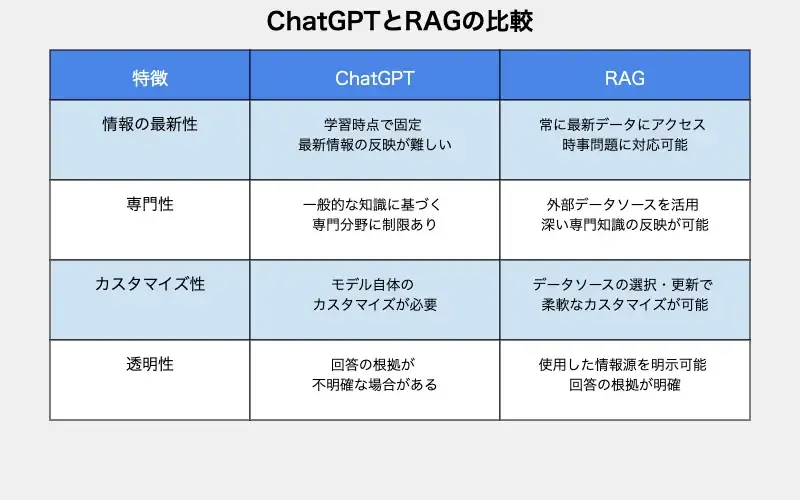
ChatGPTとRAGのもっとも顕著な違いは、情報の取得方法と更新性にあります。
ChatGPTは、事前に学習されたデータに基づいて回答を生成します。つまり、その知識は学習時点で固定されており、最新の情報や特定の領域に関する深い専門知識を反映することが難しいのです。
一方、RAGは外部のデータソースから必要に応じて情報を取得し、基に回答を生成するものです。結果として、以下のような重要な違いが生まれます。
特徴 | 説明 |
|---|---|
情報の最新性 | RAGは常に最新データにアクセスし、時事問題や変化の早い分野に正確な情報を提供 |
専門性 | 外部データソースを使い、ChatGPTよりも深い専門知識を反映した回答が可能 |
カスタマイズ性 | データソースを選択・更新でき、特定のニーズに合わせたカスタマイズが容易 |
透明性 | 使用した情報源を明示でき、回答の根拠が分かりやすく信頼性も向上 |
この違いにより、RAGはより柔軟で信頼性の高いAIソリューションを提供できるものです。
関連記事:生成AIにおけるRAGとは?活用の効果や実装時のポイント
Retrieval-Augmented Generationの仕組み

Retrieval-Augmented Generation(RAG)の仕組みは、大きくわけて「検索(Retrieval)」と「生成(Generation)」の2つのステップから成り立っています。
このアプローチにより、AIは常に最新かつ正確な情報を基に回答を生成できます。
【検索(Retrieval)ステップ】
ユーザーからの質問やプロンプトを受け取る
RAGシステムは関連する情報を外部データソースから検索する
質問にもっとも関連性の高い情報が抽出される
【生成(Generation)ステップ】
検索ステップで得られた関連情報は、大規模言語モデル(LLM)に入力される
外部情報と自身の事前学習された知識を組み合わせて、最終的な回答を生成する
RAGの特徴的な点は、このステップがシームレスに統合されていることです。つまり、ユーザーからは通常のAIチャットボットと対話しているように見えますが、背後では常に最新の情報が参照されているわけです。
この仕組みにより、RAGは以下のような利点を実現しています。
常に最新の情報を反映した回答が可能
特定のドメインや企業固有の深い知識を活用できる
回答の根拠を明示できるため、信頼性と説明可能性が向上
新しい情報や知識を容易に追加・更新できる柔軟性
RAGの実装により、AIはより人間に近い、文脈を理解した知的な対話を実現しつつあります。では、実際にRAGを使わずにChatGPTだけだと、どのような課題に直面するのか、次で詳しくみていきます。
ChatGPTだけの運用で直面する3つの課題
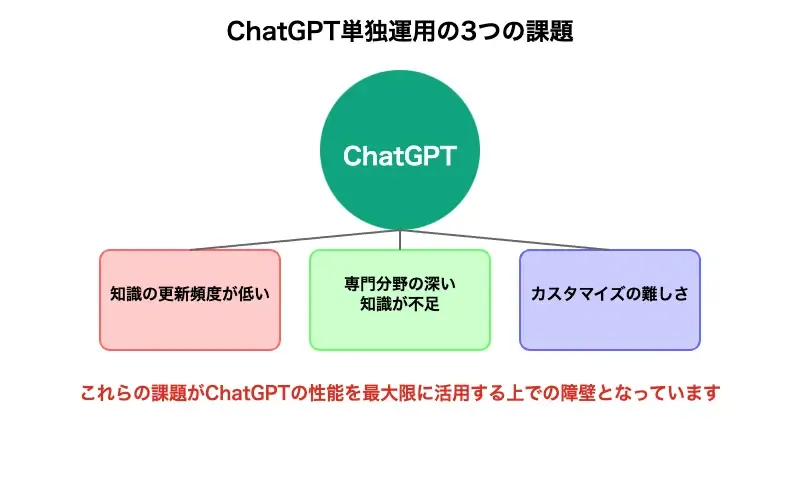
ChatGPTを単独で運用する際に企業が直面する主な課題は、以下の3つに集約されます。
知識の更新頻度が低い
専門分野の深い知識が不足
カスタマイズの難しさ
知識の更新頻度が低い
ChatGPTの知識の更新頻度が低いことは以下のような影響をもたらします。
課題 | 説明 |
|---|---|
情報の陳腐化 | ChatGPTの知識は学習時点で固定され、最新のトレンドを反映できない。 |
誤った情報の提供 | 法律や規制が変更された場合、古い情報に基づいて誤った回答を生成する可能性がある。 |
競争力の低下 | 最新の市場動向に追随できず、競合他社に後れを取る可能性がある。 |
ユーザー満足度の低下 | 最新情報を求めるユーザーのニーズに応えられず、信頼性が低下する。 |
この問題を解決するためには、定期的な再学習や外部データソースとの連携が必要となりますが、ChatGPT単独ではこの対応が困難です。
専門分野の深い知識が不足
ChatGPTは幅広い知識を持っていますが、特定の専門分野における深い知識が不足していることが大きな課題となります。
課題 | 説明 |
|---|---|
専門的な質問への不十分な回答 | 業界特有の用語に対し、表面的または不正確な回答を提供。専門家ユーザーの信頼を損なう。 |
コンテキストの誤解 | 特定の業界や分野特有のコンテキストを理解できず、不適切な回答をする恐れ。 |
イノベーションの阻害 | 深い知識が不足しているため、アイデアの創出や問題解決に限界がある。 |
リスク管理の不足 | 専門知識の不足が重大なリスクを引き起こす可能性がある。医療や法律での誤りは深刻な結果に。 |
カスタマーサポートの質の低下 | 詳細な技術サポートが提供できず、適切な解決策を提示できない場合がある。 |
この問題は、企業が ChatGPT を特定の分野や用途に適用しようとする際に大きな障壁となります。専門知識を補完するためには、追加の学習やデータ統合が必要ですが、ChatGPT単独ではプロンプトに詰め込む以外に方法がありません。
カスタマイズの難しさ
ChatGPTのカスタマイズの難しさは、企業が直面する重要な課題の1つです。この問題は以下のような影響をもたらします。
課題 | 説明 |
|---|---|
ブランドボイスの不一致 | ChatGPTは企業独自のトーンや言葉遣いを再現しにくい。 |
業務プロセスとの統合の困難さ | 既存のシステムやワークフローに組込みにくい。 |
セキュリティとプライバシーの懸念 | 機密情報や顧客データの扱いが難しい。 |
特定のユースケースへの適応の限界 | 特定の業界や部門に特化した機能の実装が難しい。 |
パフォーマンスの最適化の制限 | モデルの精度や効率性の向上が難しい。 |
主に、ChatGPTを企業の特定のニーズや要件に合わせて最適化することを困難にします。このように、AIの導入効果が限定的になったり、追加の開発コストが発生したりします。
カスタマイズの柔軟性を高めるためには、より高度なAI技術やインフラストラクチャーが必要となりますが、ChatGPT単独ではこの要求に応えることが難しいのが現状です。

そもそもChatGPTだとRAGは実行できない?

ChatGPTは確かに優れた言語モデルですが、RAG(Retrieval-Augmented Generation)を直接実行することはできません。ChatGPTの基本的な機能の範囲外に、RAGがあるためです。
ChatGPTの主な機能は、与えられた入力に基づいて文章を生成することです。特定のソースから情報を検索し、回答生成に組み込むという複雑なプロセスは含まれていません。
もう少し言えば、有料版に登録してもChatGPTが行えるのは、せいぜいインターネット検索程度です。専用のインターフェースで資料をアップロードできても、膨大な社内データから適切な情報を見つけ出して回答に使うというものではありません。

実際にRAGを実現するには、ChatGPTの大元となるモデル、つまりOpenAIが提供するGPT-3やGPT-4などのAPIを直接利用する必要があります。このAPIを使用することで外部データソースとの連携や、検索結果の統合など、RAGに必要な複雑な処理を実装できます。
したがって、ChatGPTそのものではRAGを実現できませんが、その基盤となる技術を活用することで、RAGを含むより高度なAIシステムを構築することが可能だということです。
ChatGPTのようなチャットボットの構築が基本

RAGを実装する際の基本的なアプローチは、ChatGPTのようなチャットボットを構築することから始まります。この過程では、OpenAIのAPIやAnthropicのClaudeなどの高度な言語モデルを活用し、RAGのコンポーネントと組み合わせていきます。
ざっくりとしていますが、以下のような手順を踏みます。
手順 | 説明 |
|---|---|
1. 基盤となる言語モデルの選択 | OpenAI GPT-3/4やClaude等から適切なモデルを選ぶ |
2. 外部データソースの準備 | 企業固有の文書、データベース、Webサイトなどを整理し、検索可能な形式に変換する |
3. 検索システムの実装 | ベクトル検索やセマンティック検索などの技術を用いて、ユーザーの質問に関連する情報を効率的に抽出するシステムを構築する |
4. 統合と生成 | 検索結果を言語モデルに適切に入力し、基に回答を生成するロジックを実装する |
5. インターフェースの開発 | ユーザーが簡単に対話できるチャットボットインターフェースを設計する |
このプロセスを通じて、ChatGPTのような使いやすさと、RAGの高度な情報検索・統合能力を兼ね備えたAIシステムを構築できます。ただし、この実装には高度な技術力と十分なリソースが必要であり、多くの企業にとっては専門家のサポートが不可欠となるでしょう。
RAGの導入で、自社に最適化された高精度なAIシステムを構築できます。専門知識や最新情報を反映させた信頼性の高い回答を実現し、業務効率を大幅に向上させます。

RAG vs ファインチューニングはどっちがいい?

RAG(Retrieval-Augmented Generation)とファインチューニングは、AIモデルの性能を向上させるための異なるアプローチです。どちらが適しているかは、企業のニーズや状況によって異なります。
以下に、両者の比較と使い分けの基準を示します。
基準 | RAG | ファインチューニング |
|---|---|---|
柔軟性 | ○ | △ |
最新情報の反映 | ○ | × |
初期導入の容易さ | ○ | × |
モデルの専門性 | △ | ○ |
処理速度 | △ | ○ |
データ量の要求 | △ | ○ |
RAGは外部データソースを活用するため、柔軟性が高く最新情報を反映しやすいという利点があります。一方、ファインチューニングは特定のタスクに特化したモデルを作成できることから、専門性と処理速度で優れています。
コストと効果の観点
RAGとファインチューニングのコストと効果を比較する際、導入・運用コストとパフォーマンス向上の度合いを考慮します。
RAGの導入コストは比較的低く、既存のAIモデルに外部データソースを連携させるだけで実装可能です。運用コストにおいては、データの更新や管理に主に費用がかかります。
一方、パフォーマンス向上は即時的で、最新情報を反映した回答が得られます。
ファインチューニングは、初期の導入コストが高くなる傾向にあります。大量の学習データの準備や、モデルの再学習に時間と計算リソースが必要です。
しかし、特定のタスクに特化したモデルを作成できるため、その領域でのパフォーマンスは向上します。
長期的には、RAGは柔軟性と継続的な更新が可能になることで、変化の激しい環境に適しています。ファインチューニングは、安定した環境で特定のタスクに高度な専門性が求められる場合に効果的です。
データセキュリティとコンプライアンス
データセキュリティとコンプライアンスの観点から、RAGとファインチューニングを比較すると、それぞれに異なる特徴があります。
RAGは外部データソースを使用するため、機密情報の管理が比較的容易です。
必要な情報のみを選択的に提供でき、センシティブなデータを外部に露出させるリスクを最小限に抑えられます。また、データの更新や削除が容易なことから、GDPR等のデータ保護規制への対応も柔軟に行えます。
一方、ファインチューニングでは、モデル自体に機密情報が組み込まれます。
データの完全な管理や削除が難しくなる可能性を意味し、法的リスクが高まります。特に、個人情報や企業秘密が含まれるデータセットを使用する場合は、慎重な取り扱いが必要です。
法的リスクの観点からは、RAGの方が管理しやすい傾向にあります。ただし、どちらの方法を選択する場合も、適切なデータガバナンス体制の構築と、法令遵守のための慎重なアプローチが不可欠です。
どちらも使う方法も有効
RAGとファインチューニングは、互いに排他的なアプローチではありません。実際、両方の手法を組み合わせることで、より強力で柔軟なAIシステムを構築できます。
例えば、ファインチューニングを使って特定のドメインに特化したベースモデルを作成し、そのモデルにRAGを適用して最新情報を取り込むという方法が考えられます。
この組み合わせにより、専門性の高い回答と最新情報の両方を提供できます。また、タスクの性質に応じて使いわけることも効果的です。
ただし、両方の手法を採用する場合は、システムの複雑性が増し、管理コストが上昇する可能性があります。そのため、企業のリソースと目的を十分に考慮した上で、最適な組み合わせを検討することが重要です。
RAGを実装する際に知っておきたい3つのポイント

RAGを効果的に実装するためには、以下の3つの重要なポイントを押さえます。
データ品質の確保と更新を怠らない
レスポンスタイムは最適化する
ハルシネーションの対策を行う
データ品質の確保と更新を怠らない
RAGシステムの性能は、使用するデータの品質に大きく依存します。データ品質を確保し、常に最新の状態を維持するために、適切な施策を実施することが重要です。
データの一貫性確保と不要な情報の除去
適切なタグ付けと分類情報の付与
自動的なデータベース更新の仕組み構築
定期的な人間によるレビュー実施
データの変更履歴追跡
複数の信頼できるソースからのデータ収集
どこまで行うのかは、保有するデータによって異なる点に留意してください。
レスポンスタイムは最適化する
RAGシステムのユーザー体験を向上させるためには、レスポンスタイムの最適化も不可欠です。以下の施策を実施し、システムの応答速度を改善しましょう。
データインデックスの最適化
頻繁に要求される情報のキャッシュ
データの分散処理
検索クエリ効率の改善
高性能ハードウェアの導入
ネットワーク構成の最適化
バックグラウンド処理の活用
なお、一部はクラウドで補うなども可能なため、あくまでも例として考えてください。
ハルシネーションの対策を行う
AIモデルによる誤った情報生成(ハルシネーション)は、RAGシステムの信頼性を損なう大きな問題です。以下の対策を実施することで、ハルシネーションのリスクを軽減できます。
回答の信頼性スコアリング
外部ソースとの情報照合
重要情報の人間による確認プロセス
ハルシネーション抑制プロンプトの設計
複数モデルの組み合わせ
不確実な情報の明示
情報の出典表示
ハルシネーション抑制のための追加学習
このハルシネーションに関して詳しくは、下記ページでも触れています。
関連記事:AIが作り出す嘘?生成AIの「ハルシネーション」とは
まとめ: RAGを導入するなら相談を

RAG(Retrieval-Augmented Generation)は、ChatGPTのような大規模言語モデルの能力を拡張し、企業固有の最新データを活用する技術です。
知識の更新頻度の低さ、専門分野の深い知識の不足、カスタマイズの難しさといったChatGPT単独での課題を克服し、より正確で信頼性の高いAIシステムを構築できます。
しかし、RAGの導入は単純ではありません。技術的な専門知識や、適切なリソース配分が必要となります。そのため、RAGの導入を検討する企業は、専門家のアドバイスを受けることが賢明です。
NOVELの専門家チームは、豊富な経験と最新の知見を基に、各企業の独自のニーズに合わせたRAGソリューションを提案し、導入をサポートします。RAGの導入や活用方法について、ぜひご相談ください。

よくある質問(FAQ)
RAGを構築するにはいくら費用がかかる?
RAGの構築費用は、プロジェクトの規模や複雑さによって大きく異なります。一般的に、数百万円から始まり、大規模なプロジェクトでは1,000万円を超えるケースもあります。
RAGの欠点は何ですか?
RAGにも課題があります。主な欠点として、以下が挙げられます。この課題に対処するには、適切な計画と継続的な最適化が不可欠です。
外部データ連携でシステムが複雑になる。
リアルタイム検索で応答が遅くなる。
最新データ維持にコストがかかる。
検索システムの構築に専門知識が必要。
導入・運用費用が高い。
RAGはどのような業種や企業規模で効果的ですか?
RAGは幅広い業種や企業規模で効果を発揮しますが、特に以下のような場合に有効です。
金融・法律・医療など、常に最新の専門知識が必要な業界
製造業や小売業など、大量の製品情報や在庫データを扱う企業
IT・テクノロジー企業など、急速に変化する情報を扱う業種
大規模なカスタマーサポートを行う企業
研究開発を重視する中堅・大企業
企業規模に関わらず、頻繁に更新される大量の情報を扱う組織であれば、RAGの導入価値は高いと言えます。

▌【一緒に働くメンバー募集】生成AIを活用し、顧客の課題解決をしませんか?
最後までお読みいただき、ありがとうございます。
NOVEL株式会社では、生成AIを活用して企業の業務改善や新規プロダクト開発を支援しています。
私たちは「現場に眠るデータをつなぎ人とAIが協働する社会を創る」というビジョンのもと、非IT業界が抱える複雑な課題に日々向き合っています。
もしあなたが、
新しい技術の可能性にワクワクする方
困難な課題解決を楽しめる方
自分の手で「0から1」を創り出す経験をしたい方
であれば、私たちのチームで大きなやりがいを感じていただけるはずです。 まずは、私たちがどんな未来を描いているのか、採用ページで少し覗いてみませんか?
この記事に関連するお役立ち資料を無料ダウンロード
AIを活用した業務自動化 事例BOOK
AI技術を活用した社内業務効率化の基本から、実際の導入ステップまでをわかりやすく解説しています。
下記フォームにご記入下さい。(30秒)
テックユニットは、下記のような方におすすめできるサービスです。
お気軽にご相談ください。
・開発リソースの確保に困っている方
・企業の新規事業ご担当者様
・保守運用を移管したい方
・開発の引き継ぎを依頼したい方


おすすめの記事
関連する記事はこちら
ChatGPT×RAGは可能?企業データ・社内知識を最大限に引き出すには
ChatGPTのような汎用AIを導入しただけでは、最新の情報や専門知識の不足、カスタマイズの難しさなど、様々な壁に直面します。「自社の特性に合わせたAIを構築したい」「より正確で信頼性の高い回答を得たい」といった悩みを抱える企業も少なくない...
ChatGPTとチャットボットの違いは?組み合わせによる効果も解説
企業の顧客対応の効率化、そして質の向上は、喫緊の課題であることはすでにご存知かと思います。この点で多くの企業がChatGPTやチャットボットの導入を検討していますが、どちらを選ぶべきか、その違いは何か、こう悩んでいる方も多いです。そこで今回...
企業向けに提供されている「ChatGPT Enterprise」の特徴や活用事例を徹底解説
ChatGPTは、業務効率化や人材不足解消の手段として、多くの企業がその導入を検討しています。しかし、「どのプランを選べばいいのか分からない」「自社のニーズに合うのか不安」といった声も少なくありません。このChatGPTには、企業のニーズに...
ChatGPTでナレッジマネジメントを遂行するには?おすすめのツール5選
ビジネスの世界で成功を収めるには、組織内の知識を効果的に管理し活用しなければなりません。しかし、多くの企業が膨大な情報や分散した管理、そして従業員の退職による知識の流出に悩まされています。「どうすれば社内の知識を効率的に共有できるのか」「重...
ChatGPTでコールセンター業務が変わる!具体的な活用方法と導入のポイント
コールセンターの運営において、以下の相反する要求のバランスを取るのは、至難の業です。顧客満足度を高めたいコストを抑えたいここで「AIを導入すればすべて解決!」と簡単に言えたら良いのですが、そう単純ではありません。技術の進歩は目覚ましいものの...
自社に最適なChatGPT研修を選ぶためのポイントとは【社内研修】
ChatGPTの登場以来、多くの企業はAI技術を取り入れることで業務効率の向上や新たなビジネスチャンスの創出を目指しています。しかし、効果的に活用するには、適切な知識とスキルを要します。この知識とスキルを補うために今注目されているのが、社内...
社内ChatGPTの構築方法と検討する際の比較検討ポイント
多くの企業が、業務効率化やイノベーション創出のために、AIの導入をすでに実施しています。しかし、「どのように始めればいいのか」「本当に効果があるのか」といった疑問や不安を抱えているのではないでしょうか。そこで今回は、社内ChatGPTの構築...
ChatGPTのファインチューニング事例5選!社内環境・業務改善とセキュリティ対策のバランス
自社のニーズに合ったChatGPTの活用方法が分からないChatGPTを活用しているが、さらに効果を高めたいChatGPTのファインチューニングに取り組みたいが、具体的な手順がわからない多くの企業がChatGPTの活用に乗り出している現在で...
物流業界のChatGPT活用法7選|必要性からメリット・ポイントまで解説
物流業界では、働き方改革関連法の施行により、月100時間以内の時間外労働が義務付けられています。しかし、物流業界のAI導入率は6.1%と低く、人手不足も深刻化しており、生産性の向上が喫緊の課題です。そこで今回は、物流業界におけるChatGP...
社内情報検索を最適化するChatGPTの構築方法と活用事例
社内の情報検索において、日々の業務で必要な情報を探すのに時間がかかったり、探し出せない経験はありませんか。社内のデータが膨大化した、または各部署の連携が取れていない、などのケースでは探したい情報が見つからないという状況に陥りやすいです。この...
ChatGPTの導入支援・コンサルの選び方や良いパートナーを見つけるコツを解説
ChatGPTの導入を検討しているが、具体的な活用方法がわからない導入の投資対効果を社内で説明するのが難しいAIに詳しい人材がいないため、導入が進まないChatGPTの導入は、多くの企業が直面している課題です。しかし、ChatGPTの導入は...
ChatGPTの社内利用は可能?ガイドラインや注意点も併せて解説
ChatGPTを社内で活用しようとしているものの、情報漏えいやセキュリティ面での懸念から、導入に踏み切れずにいる企業が多いのが現状です。また、単に導入するだけでは危険が伴うため、適切なガイドラインを設け、社内ルールを徹底することも求められま...
人気記事ランキング
おすすめ記事
