








AIで情報資産化|埋もれた社内データを利益に変える新常識
最終更新日:
2025.8.6




監修者情報

岡田 徹
NOVEL株式会社 代表取締役
大阪大学在学中よりエンジニアとして活動し、複数のプロダクト立ち上げを経験。
2019年2月にNOVEL株式会社を設立。
2022年より生成AI領域に特化し、
AIライティングSaaS『SAKUBUN』(累計70万回利用・2万アカウント)を企画・開発。大手メディアや人材企業・出版企業への導入実績を持つ。
現在は中堅企業向けAIコンサルティングに注力し、製造業・小売業・金融機関など業種を問わず、生成AIの導入から定着までを一気通貫で支援している。
著書: 『2冊目に学ぶ ChatGPTプロンプト攻略術』(C&R研究所、2024年)
この記事に関連するお役立ち資料




AIを活用した業務自動化 事例BOOK
無料ダウンロード
企業の成長を支える「情報」という名の資産。しかし、その多くはファイルサーバーや個人のPCに散在し、有効活用されていないのが現状ではないでしょうか。従来のキーワード検索では、本当に必要な情報へたどり着くのは困難でした。本記事では、生成AIがこの「ナレッジマネジメント」をいかに革命的に変えるのか、企業のDXを支援する代表の岡田と現役AIエンジニアの秋月が徹底的に語ります。社内に眠る情報を真の「資産」へと変える、具体的で実践的なヒントがここにあります。
生成AIが塗り替える「社内情報の探し方」
キーワード検索の限界と意味理解検索の夜明け
岡田: 秋月さん、最近のプロジェクトでAIを活用していて、特に企業のナレッジマネジメントのあり方が根本から変わるなと感じています。これまではファイルサーバーに膨大なデータがあっても、結局は目的の資料を探し出せませんでした。
秋月: 本当にそうですね。従来の検索システムは、ファイル名や本文に含まれるキーワードでの部分一致検索が基本でした。例えば、「AIに関する企画書」を探したくても、そのものズバリの言葉がファイル名や本文に入っていないとヒットしません。「人工知能の提案資料」といった少し違う表現になっているだけで、見つけられないんです。
岡田: そうなんです。頭の中では「あのプロジェクトで使った、こんな感じの資料」とイメージがあるのに、それを検索できる言葉に落とし込めない。このギャップが大きな課題でした。でも、最新の生成AI、特に大規模言語モデル(LLM)の登場で、この「曖昧な要求」を理解できるようになったのが革命的ですよね。
秋月: まさに。AIが文脈や意味を理解してくれるので、「去年の夏頃に議論した、マーケティング施策に関する議事録を探して」といった自然言語での指示が可能になります。これは単なるキーワード検索ではなく、AIが情報の「意味」を捉えて最適な答えを提示する「意味理解検索」です。

検索体験の質的変化:RAGはもう古い?
岡田: これまではRAG(検索拡張生成)※注1 といって、必要な情報をまずデータベースから検索(Search)して、それをAIに渡して回答を生成させるアーキテクチャが主流でした。でも、最近のモデル、例えばGemini 2.5 Proのようにコンテキストウィンドウ※注2 が非常に大きいモデルが出てきたことで、その前提すら変わりつつあります。
秋月: おっしゃる通りです。コンテキストウィンドウが100万トークンとかになってくると、もう分厚い本一冊分くらいの情報を丸ごと扱えます。そうなると、事前に細かく検索するより、関連しそうな資料群を全部AIに放り込んで「この中から要点をまとめて」と指示した方が早いし、精度も高いケースが増えてきました。
岡田: そうなんですよ。例えば、過去1年分の議事録を全部テキスト化してAIに渡せば、時系列に沿ったプロジェクトの変遷を勝手に整理・要約してくれる。わざわざRAGの仕組みを組まなくても、力技で解決できてしまう。これは大きなパラダイムシフトです。
秋月: 開発の観点からも、RAGのベクトル検索の精度調整は意外と職人芸的な部分があったので、巨大なコンテキストウィンドウで解決できるなら、開発コストも運用コストも下げられる可能性がありますね。
主要な大規模言語モデルの比較
モデル名 | 開発元 | 最大コンテキストウィンドウ(トークン) | 特徴 |
GPT-O3 | OpenAI | 128,000 | 高速な応答と高いマルチモーダル性能。 |
Claude 4 sonnet/opus | Anthropic | 200,000 | 長文の読解・生成能力に優れ、複雑な指示にも強い。 |
Gemini 2.5 Pro | 1,000,000 (最大2,000,000) | 圧倒的なコンテキストウィンドウ。動画や音声の理解も可能。 |
散在するナレッジを「資産」に変えるAI活用術
ファイルサーバーの混沌を整理・構造化する
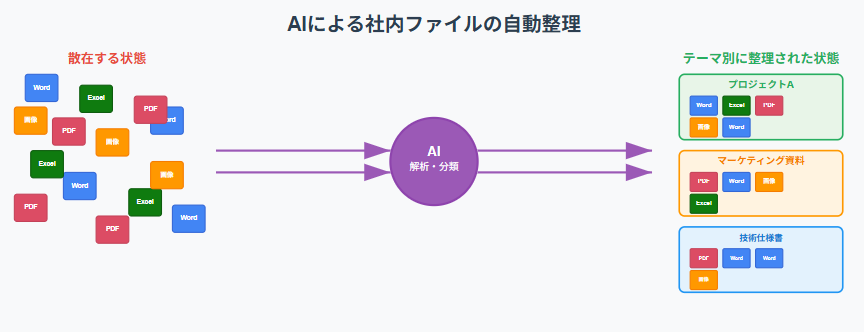
岡田: 多くの企業が直面しているのが、長年蓄積されてきたファイルサーバー問題です。フォルダの階層構造は作る人によってバラバラだし、ファイル名も統一されていない。これが情報のサイロ化を生んでいます。
秋月: そうしたカオスな状態のデータも、AIを使えば整理・活用への道筋が見えてきます。例えば、ファイルの中身をAIが読み取り、内容に基づいて自動でタグ付けしたり、関連性の高いドキュメント同士を紐付けたりすることができます。図面やExcelファイルの中身もある程度読み取って構造化できますね。
岡田: まさに。過去のプロジェクトの要件定義書やスケジュール表をAIが整理してくれれば、「似たような新規プロジェクト」が立ち上がった時に、「過去の類似案件の資料を参考に、新しいプロジェクトの叩き台を作って」と指示するだけで、精度の高い雛形が一瞬で完成します。これは生産性の向上に直結しますよね。
「書くだけ」だった議事録を戦略的資産へ
岡田: 議事録も宝の山です。我々の社内では、あえて1つのドキュメントに時系列で全議事録を追記していくスタイルを取っていますが、これがAI活用と非常に相性がいい。
秋月: ページが分かれていないので、単純に全文コピーしてAIに渡せますからね。Notionのようにページが細かく分かれていると、一括でエクスポートしてAIに処理させるのが意外と手間だったりします。
岡田: その通りです。1年分の議事録を丸ごとAIに投げれば、「Aというテーマに関する議論の変遷をまとめて」とか、「決定事項だけをリストアップして」といった指示に即座に応えてくれます。これは、担当者が変わった時や、過去の経緯を素早く把握したい時に絶大な効果を発揮します。
ソースコードや設計書も検索可能なナレッジに
秋月: 開発部門に目を向けると、ソースコードはGitHubなどでバージョン管理されているので比較的探しやすいですが、それに付随する設計書や仕様書が散逸しているケースは多いです。
岡田: ええ。そういったドキュメント類もAIの検索対象に含めることで、「この機能はどういう意図で実装されたのか?」を、コードだけでなく関連ドキュメントからも探せるようになります。結果として、仕様の理解が早まり、メンテナンス性や改修の品質が向上します。
これからのナレッジマネジメント基盤の作り方
ステップ1:データ整理とクラウドへの集約
岡田: ここまでAI活用の話をしてきましたが、大前提として、AIが読み取れる場所にデータがなければ始まりません。多くの大企業では、まだ社内のローカルサーバーにデータを置いているケースが多い。
秋月: まずはそこからですね。散在しているデータを整理し、クラウドストレージのような場所に集約することが最初のステップになります。
岡田: まさにそのデータ整理と活用のコンサルティングで急成長したのが、米国のパランティア・テクノロジーズ(Palantir Technologies)という会社です。彼らは軍事分野での実績が有名ですが、製造業など民間企業に対しても、まずは顧客のデータを整理・統合し、意思決定に使える状態にすることから始めます。
秋月: 日本企業も同じアプローチが必要ですね。いきなりAIを導入するのではなく、まずは自分たちの情報資産がどこに、どのような状態であるかを把握し、一元的にアクセスできる環境を整える。この地道な作業が、後のAI活用の成否を分けます。
ステップ2:目的に応じたAIモデルとアーキテクチャの選定
岡田: データ基盤が整ったら、次にそれをどう活用するかのアーキテクチャ設計です。先ほど話したように、巨大なコンテキストウィンドウを持つモデルを使うのか、あるいは従来通りRAGの仕組みを構築するのか。
秋月: これは目的やデータの量、更新頻度によって変わってきます。例えば、社内規定やマニュアルのように更新頻度が低く、正確性が求められる情報の検索であれば、RAGが依然として有効です。一方で、複数の議事録やレポートを横断的に分析してインサイトを得たい、といった用途であれば、Geminiのような巨大コンテキストモデルが力を発揮します。
岡田: 結局、「何を知りたいのか」「どういう業務を効率化したいのか」という目的を明確にすることが最も重要です。我々のような専門家がお客様と対話する際も、まずはその課題の解像度を上げることから始めます。ツールの導入は、その課題解決のための手段でしかありません。
ステップ3:プロトタイピングと現場への導入
秋月: 仕様を固めたら、まずは小規模なプロトタイプ開発から始めるのが定石です。例えば、特定の部署のデータだけを対象にした検索システムを構築し、実際に使ってもらってフィードバックを得る。
岡田: そのプロセスが不可欠ですね。AIは魔法の杖ではなく、現場の業務フローに組み込んで初めて価値を生みます。実際に使ってもらうことで、「こういう検索結果の表示方法の方が見やすい」「こんな機能も欲しい」といった具体的なニーズが見えてきます。それを元に改善を繰り返していくアジャイルな開発スタイルが、AIプロジェクトでは特に重要になります。最終的には、全社員が日常的にAIアシスタントに話しかけるようにして社内情報を引き出せる状態が理想形です。
まとめ:ナレッジは「探す」から「対話で引き出す」時代へ
生成AIの登場により、企業のナレッジマネジメントは大きな転換点を迎えています。もはや情報は、フォルダの階層を辿って「探す」ものではありません。AIとの「対話」を通じて、文脈に応じた最適な形で「引き出す」ものへと変わります。
この変革の波に乗るためには、
社内に散在するデータを整理・集約する
目的に合ったAI活用のアプローチを設計する
現場のフィードバックを取り入れながらアジャイルに開発を進める
というステップが鍵となります。
社内に眠る膨大な情報は、これからの時代を勝ち抜くための競争力の源泉です。この「情報資産」を最大限に活用し、ビジネスを加速させるための第一歩を、今こそ踏み出すべきではないでしょうか。
その業務課題、AIで解決できるかもしれません
「AIエージェントで定型業務を効率化したい」 「社内に眠る膨大なデータをビジネスに活かしたい」
このような課題をお持ちではありませんか?
私たちは、お客様一人ひとりの状況を丁寧にヒアリングし、本記事でご紹介したような最新のAI技術を活用して、ビジネスを加速させるための最適なご提案をいたします。
AI戦略の策定から、具体的なシステム開発・導入、運用サポートまで、一気通貫でお任せください。
「何から始めれば良いかわからない」という段階でも全く問題ありません。 まずは貴社の状況を、お気軽にお聞かせください。
>> AI開発・コンサルティングの無料相談はこちら
注釈
※注1 RAG(検索拡張生成、Retrieval-Augmented Generation): 大規模言語モデルが回答を生成する際に、外部の知識データベースから関連情報を検索し、その情報を参照して回答の正確性や網羅性を向上させる技術。
※注2 コンテキストウィンドウ: 大規模言語モデルが一度に処理できる情報量(テキストの長さ)の上限。このサイズが大きいほど、より長く複雑な文脈を理解できる。トークンという単位で表される。
FAQ(よくある質問)
Q1. 生成AIを導入すれば、今あるファイルサーバーをそのまま使えますか?
A1. 技術的には可能ですが、推奨されません。AIが最大限の性能を発揮するためには、まずファイル名やフォルダ構成をある程度正規化し、不要なデータを整理することが重要です。また、アクセス権の管理やセキュリティの観点からも、データを一度クラウドなどの適切な基盤に移行し、整理してからAIと連携させるのが最も効果的かつ安全です。
Q2. AIに社内情報を渡すことのセキュリティが心配です。
A2. ごもっともな懸念です。対策として、Microsoft AzureやGoogle Cloudなどのセキュアなクラウド環境内で利用できるAPIサービスを選ぶ方法があります。これらのサービスでは、入力したデータがAIモデルの再学習に使われないよう設定することが可能です。また、より機密性の高い情報を扱う場合は、社内サーバーで運用できるオープンソースの言語モデルを利用するなど、セキュリティ要件に応じた構成を選択することが重要です。
Q3. AIによるナレッジ検索システムの導入には、どれくらいの費用と期間がかかりますか?
A3. 対象とするデータの量や種類、求める機能の複雑さによって大きく変動します。特定の部署のドキュメント数万件を対象とした基本的な意味検索システムのプロトタイプであれば、2〜3ヶ月程度の期間で構築することも可能です。まずは解決したい課題と予算感をご相談いただければ、実現可能なスコープをご提案いたします。
この記事に関連するお役立ち資料を無料ダウンロード
AIを活用した業務自動化 事例BOOK
AI技術を活用した社内業務効率化の基本から、実際の導入ステップまでをわかりやすく解説しています。
下記フォームにご記入下さい。(30秒)
テックユニットは、下記のような方におすすめできるサービスです。
お気軽にご相談ください。
・開発リソースの確保に困っている方
・企業の新規事業ご担当者様
・保守運用を移管したい方
・開発の引き継ぎを依頼したい方









おすすめの記事
関連する記事はこちら
「提案は立派なのに何も変わらない」を防ぐーー1問で分かるAI導入コンサルの本当の見極め方
AI導入コンサル選びの失敗パターン3つと、面談で使える見極め方を実務経験から解説。「論点整理だけ」「開発はできるがコンサルはできない」など現場で起きる地雷の正体とは?この記事でわかること-AI導入コンサル選びの失敗は「提案の華やかさ」で選ぶ...
AI外注 vs 内製 どっちが正解?3年やって出た答えは"どっちもコケる"
AI外注か内製かで悩む中小企業向けに、どちらを選んでもコケる理由と、成果が出るハイブリッドの分業モデルを実務経験から解説します。この記事でわかること- フル外注もフル内製も、どちらを選んでも失敗しやすい構造的な理由がある- AI導入の失敗は...
そのデータ、本当にAIに使えますか?活用前に整理したい2つのこと
「AIを使いたいけど、うちのデータって本当に使えるのかな……?」そんな不安を感じている企業は少なくありません。ChatGPTなどの生成AIを導入しても、社内データの状態が整っていなければ、期待した答えが返ってこないことはよくあります。そこで...
Excel・Accessがもう限界?移行を判断する10のサインと、中小企業の現実的な進め方
ある日突然、業務が止まる前に「受注管理のExcelを2人で同時に開いたら壊れた。バックアップがなく、1週間分のデータが消えた。」「Accessのデータベース、作った担当者が退職してから誰も触れていない。クラッシュしたら終わり。」「月末の集計...
AI時代に必要なデータ基盤とは?整理しないとAIは使えない
「AIを入れたのに使えない」の本当の原因「ChatGPTを社内に導入したけど、精度が出なくて結局使われていない」「AIで月次レポートを自動化したいのに、どこから手をつければいいかわからない」こうした声は、AI導入を検討している中小企業のあち...
DX推進室がなくても大丈夫!現場主導のAI活用スモールスタート術
「AIの導入は、専門のDX推進室や優秀なAIエンジニアがいる大企業だけの話だ」 「我が社には推進できる人材がいないから…」企業の規模を問わず、多くのビジネスリーダーがAIの可能性を感じながらも、人材不足を理由に最初の一歩を踏み出せずにいます...
AIで営業の優先度付けを自動化|売れる3%に集中する方法
「なぜ、あの人だけが常に高い成果を上げ続けるのか?」 多くの営業組織では、一握りのトップセールスが全体の売上の大半を支えるという、いわゆる「属人化」が長年の課題となっています。彼らの持つ勘や経験を組織に共有するのは難しく、多くの営業担当者は...
方法から入るAI導入は失敗する|現場起点のAI定着設計術
「最新のAIツールを導入したが、現場では全く使われず、ライセンス費用だけが無駄になっている…」 これは、AI導入に取り組む多くの企業が直面する、決して珍しくない現実です。鳴り物入りで始まったプロジェクトが、なぜ現場に受け入れられず、静かに形...
AIは指示待ちから先回りへ。次世代AIエージェントとは
これまで私たちが慣れ親しんできたChatGPTをはじめとする生成AIは、非常に賢いアシスタントでした。しかし、その基本はあくまで「指示待ち」。ユーザーがプロンプトを入力して初めて、その能力を発揮する受動的な存在でした。しかし今、その常識が大...
AI-OCRとは?従来のOCRとの違いと進化した業務活用術
「紙の書類を手作業でデータ入力するのに膨大な時間がかかっている」「過去にOCRを導入したが、認識精度が低く、結局人の手で修正ばかりで使えなくなってしまった」多くの企業で、このような課題が業務効率化の壁として立ちはだかっています。しかし、その...
AI活用の成否を分ける!なぜ社内データのクラウド移行が第一歩なのか
多くの企業でAI活用が経営の重要課題となる中、「何から手をつけるべきか」という声がよく聞かれます。その第一歩として、実は「社内データの置き場所」が極めて重要になることは、あまり知られていません。多くの企業では、長年の慣習やセキュリティへの漠...
AI社内検索で『あの資料どこ?』を解決!図面・仕様書を5秒で探す方法
「あの案件の図面、どこだっけ?」「似たような仕様書、前に作ったはずなのに見つからない…」オフィスでこんな会話が聞こえてきたら、それは危険信号かもしれません。多くの企業、特に製造業や建設業では、日々膨大な量の文書、図面、仕様書が作成され、ファ...
人気記事ランキング
おすすめ記事



