









この記事に関連するお役立ち資料

AIを活用した業務自動化 事例BOOK
無料ダウンロード
大量のデータを処理し、的確な回答を生成するLLM(Large Language Model)に注目が集まる一方で、その限界や課題も少なくありません。
例えば、情報の正確性や最新性の確保、専門分野への適応、そして説明可能性の向上など、LLMの活用には様々な課題があります。こうした課題を解決する技術が、RAG(Retrieval-Augmented Generation)です。
今回は、RAGとLLMの組み合わせがもたらす相乗効果や、実際の導入方法について詳しく解説します。この記事を読むことで、企業に最適な生成AI戦略を見出すヒントが得られるはずです。
RAGとLLMの組み合わせで企業の生成AI活用を最適化。専門知識を活かした導入支援で、貴社のAI戦略を成功に導きます。

RAGはLLMの長所を伸ばし欠点を補完する

RAG(Retrieval-Augmented Generation)は、LLM(Large Language Model)の能力を最大限に引き出し、同時にその弱点を補うアプローチです。要点となるのは、外部のデータベースから関連情報を検索し、LLMの入力として活用することです。
RAGはLLMの長所である自然言語理解と生成能力を維持しつつ、以下の点で大きな改善をもたらします。
外部データソースを使い、最新かつ正確な情報を提供できる
特定分野のデータを組込み、LLMの専門性を向上できる
回答の根拠を明示し、説明可能性を高める
データソース変更で異なる用途や分野に適応できる
つまり、RAGはLLMの柔軟な言語処理能力を活かしながら、その弱点である事実の正確性や最新性の欠如を補完するわけです。企業は生成AIの導入において、より信頼性の高い、カスタマイズされたソリューションを実現できます。
LLMとRAGの基本をわかりやすく確認
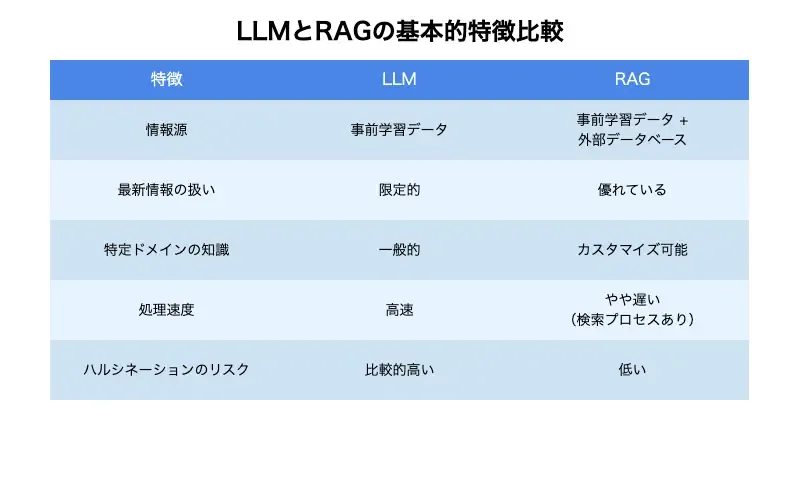
とはいえ、簡単にまとめても難しいはずです。LLMとRAGの主な特徴を比較表で示すと、以下のようになります。
特徴 | LLM | RAG |
|---|---|---|
情報源 | 事前学習データ | 事前学習データ + 外部データベース |
最新情報の扱い | 限定的 | 優れている |
特定ドメインの知識 | 一般的 | カスタマイズ可能 |
処理速度 | 高速 | やや遅い(検索プロセスあり) |
ハルシネーションのリスク | 比較的高い | 低い |
柔軟性 | 高い | 高い(さらに正確性が向上) |
実装の複雑さ | 比較的簡単 | やや複雑(外部データベースの管理が必要) |
以下で、LLMとRAGの基本をわかりやすく解説します。
LLM(Large Language Model)
LLM(Large Language Model)とは、膨大な量のテキストデータを学習し、人間のような自然言語処理能力を持つAIモデルのことです。
GPT-3やBERTなどが代表例として挙げられ、文章の生成、翻訳、要約、質問応答など、多岐にわたる言語タスクをこなすことができます。
その特徴は、事前学習された知識を基に、与えられた文脈に応じて適切な応答を生成できる点です。特定のタスクに特化したモデルを一から作る必要がなくなり、様々な用途に柔軟に対応できるようになりました。
LLMについての詳細は、こちらでさらに詳しく解説しています。
RAG(Retrieval-Augmented Generation)
RAG(Retrieval-Augmented Generation)は、外部データベースから関連情報を検索する技術のことです。その情報をLLMの入力に組み込むことで、より正確で最新の情報に基づいた回答を生成を促します。
例えば、企業の製品情報や最新のニュースなど、常に更新される情報を扱う場合、RAGは特に有効です。LLMの柔軟な言語処理能力と、RAGによる外部データベースの情報を組み合わせることで、より信頼性の高い回答を生成できます。
RAGの詳細については、こちらで詳しく解説しています。
LLMにおけるRAGの仕組み

RAG(Retrieval-Augmented Generation)は、以下のステップでLLM(Large Language Model)の能力を拡張し、より正確で最新の情報を提供します。
ステップ | 説明 |
|---|---|
クエリ受信 | ユーザーの質問や指示を受け取る |
クエリ分析 | LLMがクエリを解析し、必要な情報を特定 |
情報検索 | 外部データベースから関連情報を検索 |
コンテキスト生成 | 検索結果を基に適切なコンテキストを生成 |
LLMへの入力 | コンテキストとオリジナルのクエリをLLMに入力 |
回答生成 | コンテキストと知識を組み合わせて回答を生成 |
後処理 | 回答を整形し、必要に応じて情報源の引用や確信度スコアを追加 |
出力 | 最終的な回答をユーザーに提示 |
この仕組みにより、RAGはLLMの柔軟な言語処理能力を維持しつつ、外部データソースからの最新かつ正確な情報を組み込むことができます。このように、より信頼性の高い、カスタマイズされた回答を生成することが可能となり、企業の多様なニーズに応える効率的なソリューションとなるのです。
LLMとRAGの5つの相乗効果

LLM(Large Language Model)とRAG(Retrieval-Augmented Generation)の相乗効果により、企業は従来のLLMの限界を超え、より高度で信頼性の高いAIソリューションを実現できます。
以下に、LLMとRAGの組み合わせがもたらす5つの主要な効果を詳しく説明します。
情報の正確性と最新性の向上
コンテキスト理解の深化
生成内容の多様性と創造性の拡大
カスタマイズと専門性の強化
説明可能性とトレーサビリティの向上
1. 情報の正確性と最新性の向上
従来のLLMは、学習データの範囲内でのみ正確な情報を提供できましたが、RAGの導入により、常に最新の外部データソースを活用できます。例えば、企業の製品情報や市場動向などの頻繁に更新される情報を扱う場合などに有効です。
また、ユーザーに提供する情報の信頼性が向上し、誤った情報や古い情報に基づく判断のリスクを最小限に抑えることができます。RAGは「ハルシネーション」と呼ばれるLLMの誤った情報生成のリスクも軽減します。
関連記事:AIが作り出す嘘?生成AIの「ハルシネーション」とは
2. コンテキスト理解の深化
LLMは、与えられた文脈に基づいて理解と生成を行いますが、RAGを導入することで、より広範囲かつ深いコンテキストを理解できます。
ユーザーの質問や指示に関連する情報を外部データベースから検索し、LLMの入力に組み込むことで、より豊富な背景情報を基に回答を生成できるのです。
単なる表面的な回答ではなく、質問の背景にある意図や関連する文脈を深く理解した上での回答が可能になります。結果として、より深い洞察と理解を得ることができ、複雑な問題や多面的な質問に対しても適切に対応できます。
3. 生成内容の多様性と創造性の拡大
LLMは事前学習されたデータに基づいて回答を生成するため、その創造性には一定の限界がありました。しかし、RAGを導入することで、外部データソースからの多様な情報を活用し、より豊かで独創的な内容を生成できます。
マーケティングキャンペーンの企画や製品開発のブレインストーミングなど、創造性が求められる場面で特に効果を発揮します。さらに、異なる分野の情報を組み合わせることで、横断的な洞察やソリューションを生み出すことも可能です。
4. カスタマイズと専門性の強化
企業固有のデータベースや、業界特有の専門文献をRAGの検索対象として設定することで、LLMは該当分野の深い専門知識を活用した回答を生成できます。
一般的なAIアシスタントでは対応が難しかった高度な専門的質問にも、正確かつ詳細に答えることが可能です。さらに、企業の内部文書や過去の事例などを組み込むことで、組織特有の文脈や慣行を理解した上での回答も実現します。
顧客サポート、社内ナレッジ管理、専門的なコンサルティングなど、幅広い分野での応用が期待できます。
5. 説明可能性とトレーサビリティの向上
従来のLLMでは、生成された回答の根拠や情報源を明確に示すことが難しいケースがありました。一方、RAGなら回答の生成に使用した外部データソースの情報を明示できます。
また、トレーサビリティの向上により、AIの判断プロセスを後から検証することもしやすくなります。誤った情報が提供された場合、その原因を特定し、データソースの更新や検索アルゴリズムの調整など、適切な対策を講じることができるのです。
このような説明可能性とトレーサビリティの向上は、特に規制の厳しい業界や、高度な説明責任が求められる場面では特に有効でしょう。
RAGとLLMの組み合わせによる効果的な生成AI活用。専門家による導入支援で、貴社に最適なソリューションを見つけましょう。

RAGをLLMに実装する基本の方法

RAG(Retrieval-Augmented Generation)をLLM(Large Language Model)に実装する基本的な方法は、以下の6つのステップから構成されます。
データソースの準備と前処理
ベクトルデータベースの構築
検索システムの最適化
LLMの選択とセットアップ
RAGパイプラインの構築
システムの評価と最適化
1. データソースの準備と前処理
RAGシステムの構築において、最初のステップとなるのがデータソースの準備と前処理です。
まず、企業内の既存のドキュメント、データベース、Webサイトなど、利用可能なすべての情報源を特定します。次に、収集したデータを整理し、以下のような手法で不要な情報や重複を除去する流れです。
テキストのクリーニング
フォーマットの統一
メタデータの付与
この前処理を丁寧に行うことで、後続のステップでのデータ活用がスムーズになり、最終的にLLMの応答品質の向上につながります。データの品質と量のバランスを取ることが、効果的なRAGシステムの構築には不可欠です。
2. ベクトルデータベースの構築
ベクトルデータベースの構築は、RAGシステムの中核です。このデータベースは、前処理したテキストデータを高次元のベクトル空間に変換し、効率的な検索を可能にします。
ベクトルデータベースの構築プロセスは以下のようになります。
ステップ | 説明 |
|---|---|
テキストのエンコーディング | テキストを数値ベクトルに変換 |
インデックス作成 | 高速検索のためのデータ構造を構築 |
メタデータの関連付け | 元のテキストやソース情報と紐付け |
ベクトルデータベースを使用することで、意味的に類似したテキストを高速に検索できます。LLMが質問に関連する情報を迅速に取得し、より正確で文脈に沿った回答を生成できます。
ベクトルデータベースの詳細については、こちらで詳しく解説していますので、ぜひご覧ください。
3. 検索システムの最適化
検索システムの最適化では、ユーザーの質問に対してもっとも関連性の高い情報を効率的に取得することを目指します。
検索システムの最適化は継続的なプロセスであり、ユーザーのフィードバックや使用データの分析に基づいて常に改善を重ねます。LLMがより正確で関連性の高い情報を基に回答を生成できるようになり、RAGシステム全体の性能向上につながるのです。
4. LLMの選択とセットアップ
RAGシステムと組み合わせる適切なLLMを選び、効果的にセットアップすることで、高品質な応答生成が可能になります。
例えば、GPT-3やGPT-4などのOpenAIのモデル、Google の PaLM、Meta の LLaMA など、様々な選択肢があります。企業の規模や目的に応じて、適切なモデルを選択することが重要です。
LLMの選択とセットアップは、RAGシステムの中でも特に専門知識が必要な部分です。必要に応じて、AIの専門家やコンサルタントの助言を受けることも検討しましょう。
5. RAGパイプラインの構築
RAGパイプラインの構築は、これまでのステップで準備した各コンポーネントを統合し、一貫したシステムとして機能させる工程です。このパイプラインにより、ユーザーの質問から最終的な回答生成までのフローがスムーズに行われます。
RAGパイプラインの効果的な構築により、ユーザーの質問に対して、正確で文脈に沿った回答を迅速に提供できる基盤が整うのです。結果、ユーザー体験の向上と、システムの信頼性確保につながります。
6. システムの評価と最適化
RAGシステムの構築後、大切なのはその性能を評価し、継続的に最適化することです。この段階では、システムの出力品質、応答速度、ユーザー満足度などを総合的に分析し、改善点を特定します。
プロセス | 説明 |
|---|---|
性能指標の設定 | 正確性、応答時間、関連性スコア、ユーザー満足度 |
テストデータセット | 様々な質問と期待回答を含むデータセットを準備 |
自動評価 | BLEU、ROUGEなどの評価指標やカスタム評価スクリプトを使用 |
人間による評価 | エキスパートレビューとユーザーフィードバック収集 |
エラー分析 | 誤答や不適切応答のパターン特定と根本原因の追究 |
継続的な改善 | データソース拡充、アルゴリズム調整、LLMのファインチューニング、プロンプト最適化 |
システムの評価と最適化は一度で終わるものではなく、継続的なプロセスです。ユーザーのニーズや技術の進歩に合わせて、常にシステムを進化させていく必要があるでしょう。
RAGとLLMを組み合わせて活用する3つの方法

RAGとLLMを組み合わせて活用する3つの方法には、以下が挙げられます。
カスタマーサポートの効率化
社内ナレッジ管理の最適化
コンテンツの生成
カスタマーサポートの効率化
RAGとLLMを組み合わせたカスタマーサポートシステムは、顧客満足度の向上と運用コストの削減を同時に実現します。以下から関連情報を迅速に検索し、LLMがその情報を基に自然な対話形式で回答を生成します。
製品マニュアル
FAQデータベース
過去の問い合わせ履歴
また、頻繁に更新される情報(例:サービスの利用規約や料金プラン)についても、常に最新の正確な情報を提供できます。
このアプローチにより、24時間365日の迅速な対応が可能になり、人間のオペレーターの負担を軽減しつつ、複雑な問い合わせにも対応できます。
社内ナレッジ管理の最適化
RAGとLLMを活用した社内ナレッジ管理システムは、企業内の膨大な情報を効率的に整理し、必要な時に必要な情報を即座に提供できます。
社内文書
プロジェクト報告書
議事録
社内規定
などの多様なデータソースを統合し、従業員が簡単にアクセスできる知識ベースを構築します。例えば、新入社員が業務手順について質問した場合、システムは関連する社内マニュアルや過去の事例から適切な情報を抽出し、分かりやすく説明するなどです。
結果、情報の分散や属人化を防ぎ、組織全体の知識共有と学習を促進します。退職者の知識流出を防ぎ、組織の知的資産を効果的に保持することも可能でしょう。
コンテンツの生成
RAGとLLMを組み合わせたコンテンツ生成システムは、高品質で信頼性の高い文章を効率的に作成する方法です。企業の製品情報、市場データ、業界レポートなどの信頼できるソースから関連情報を抽出します。
例えば、マーケティング部門が新製品のプレスリリースを作成する場合、システムは製品の技術仕様、市場動向、競合製品の情報などを自動的に収集し、基に魅力的な文章を生成するといった具合です。
コンテンツ制作のスピードと量を向上させつつ、一貫した品質と正確性を維持できます。人間の編集者は、生成されたコンテンツの最終チェックや微調整に集中できるため、創造的な作業により多くの時間を割くことも可能です。
RAG×LLMとファインチューニングの比較

RAG×LLMとファインチューニングは、両者ともLLMの性能を向上させる手法ですが、特徴、目的、適用シーンに違いがあります。
特徴 | RAG×LLM | ファインチューニング |
|---|---|---|
外部知識の利用 | 〇 | × |
モデルの変更 | × | 〇 |
実装の容易さ | 〇 | △ |
リアルタイム性 | 〇 | × |
特定ドメインへの適応 | 〇 | 〇 |
計算リソース要求 | △ | 〇 |
データ更新の容易さ | 〇 | × |
RAG×LLMは、外部知識を動的に取り込むことで、LLMの回答を補強する手法です。外部知識を柔軟に利用でき、実装が比較的容易です。
一方、ファインチューニングは、特定のタスクや領域に対してLLMを学習します。特定のタスクに対して高度な最適化が可能ですが、実装にはより多くの専門知識と計算リソースが必要です。
使い分けの指針
RAG×LLMとファインチューニングの選択は、プロジェクトの要件や利用可能なリソースに応じて行うべきです。以下に、それぞれの手法が適している状況とユースケースを示します。
【RAG】
RAG×LLMを選択すべき状況 | 例 |
|---|---|
頻繁に更新される情報を扱う必要がある場合 | 最新のニュース記事を基にした質問応答システム |
企業固有の知識ベースを活用したい場合 | 社内文書を参照するカスタマーサポートチャットボット |
データのプライバシーや機密性が重要な場合 | 医療記録を参照する診断支援システム |
【ファインチューニング】
ファインチューニングを選択すべき状況 | 例 |
|---|---|
特定の専門分野で高度な性能が求められる場合 | 法律文書の自動生成や分析 |
タスクが明確で、学習データが十分に用意できる場合 | 特定の製品ラインに特化した感情分析モデル |
レスポンス速度が極めて重要な場合 | リアルタイムの言語翻訳システム |
もちろん、プロジェクトの規模や目的、利用可能なリソース、データの性質を考慮し、適切な手法を選択することが重要です。場合によっては、両手法を組み合わせることで、より高度なAIシステムを構築することも可能です。
まとめ:RAGを導入するために

RAG(Retrieval-Augmented Generation)は、LLM(Large Language Model)の能力を大きく拡張します。正確性の向上、最新情報の反映、専門性の強化など、RAGがもたらす利点は多岐にわたるのです。
RAGの導入を検討している企業は、まず自社のニーズと課題を明確にすることから始めるべきです。カスタマーサポート、ナレッジ管理、コンテンツ生成など、どの領域でRAGを活用できるか検討してください。
NOVELでは、RAGとLLMの組み合わせで企業のAI活用を最適化します。貴社に最適な戦略を見出すためにも、まずは気軽にご相談ください。

よくある質問(FAQ)
LLMにおけるRAGとは?
LLMにおけるRAGとは、大規模言語モデル(LLM)の能力を拡張し、より正確で最新の情報を提供するための手法のことです。RAGは、外部のデータベースから関連情報を検索し、LLMの入力として活用します。
LLMの柔軟な言語処理能力を維持しつつ、常に最新かつ正確な情報に基づいた回答が可能になります。
ファインチューニングとRAGの違いは何ですか?
ファインチューニングとRAGは、LLMの性能を向上させる手法ですが、アプローチが異なります。ファインチューニングは、LLMのパラメータを特定のタスクや領域に合わせて調整する方法で、モデル自体を変更します。
一方、RAGは外部知識を動的に活用し、モデル自体は変更せずに回答の質を向上させる技術です。詳細はこちらをご覧ください。
機械学習におけるRAGとは?
機械学習におけるRAGは、クエリに関連する情報を外部データベースから検索し、その情報を言語モデルの入力として使用して回答を生成します。この方法により、モデルは事前学習された知識だけでなく、最新かつ正確な外部情報も活用できます。
RAGを導入するための初めのステップは?
RAGを導入するための初めのステップは、専門家に相談することです。導入には、適切なデータソースの選定、ベクトルデータベースの構築、LLMの選択など、複雑な要素が絡みます。
NOVELでは、豊富な経験と最新の知見を持つチームが、RAGの力を最大限に活用し、貴社のAI戦略を次のレベルへ引き上げるお手伝いをいたします。

この記事に関連するお役立ち資料を無料ダウンロード
AIを活用した業務自動化 事例BOOK
AI技術を活用した社内業務効率化の基本から、実際の導入ステップまでをわかりやすく解説しています。
下記フォームにご記入下さい。(30秒)
テックユニットは、下記のような方におすすめできるサービスです。
お気軽にご相談ください。
・開発リソースの確保に困っている方
・企業の新規事業ご担当者様
・保守運用を移管したい方
・開発の引き継ぎを依頼したい方


おすすめの記事
関連する記事はこちら
生成AIを用いたアンケート分析:メリットと活用のコツ
アンケート分析は、顧客の声を理解し事業戦略を立てる上で欠かせません。しかし、従来の人手によるアンケート分析では、大量データの処理や複雑な分析に膨大な時間と労力が必要です。本記事では、これらの課題を解決する生成AIとChatGPTを活用したア...
生成AIで顧客分析・顧客フィードバック分析を効率化!導入手順とメリットとは?
顧客の満足度向上と長期的な関係構築は、どの企業にとっても重要な目標です。これを実現するには、顧客のニーズを正確に把握する必要があります。しかし、従来の分析手法では、顧客分析に時間と労力がかかりすぎてしまいます。そこで注目を集めているのが、生...
【2024年最新】AI/生成AIのパーソナライズ事例と導入ステップを徹底解説
「生成AIを活用したいけど、どうすればパーソナライズできるのか分からない」「生成AIのパーソナライズ導入にはリスクがあるのではないか」というお悩みはありませんか?生成AIを用いたパーソナライズは、顧客体験の改善や業務プロセスの最適化など、多...
業務に使える文書作成の生成AIツール10選|活用例や注意点も解説
ビジネスの現場では文書を作成する機会が多く、「文書作成に時間がかかりすぎる」「クオリティの高い文章を効率的に作成したい」などの悩みは尽きません。しかし、一般的なAIライティングツールでは、ビジネスの現場で求められる高度な要求に応えきれないこ...
生成AIでRFP(提案依頼書)への回答を効率化!メリットと具体的な手順を解説
RFP(提案依頼書)の回答作成において、「時間がかかりすぎる」「ミスが心配」「もっと効率的に作成できないか」といった悩みを抱えている方も多いのではないでしょうか。RFPには一定の形式や構造があり、テンプレートで作成できることから、生成AIと...
生成AIによる報告書の自動作成|選定基準や導入効果、注意点について
報告書で作成に時間がかかり、ミスの心配も付きまとう…そのような悩みを抱えていませんか?生成AIを活用すれば、作成時間の大幅短縮やコスト削減、さらには品質の向上まで実現可能です。本記事では、AIを使った報告書の自動作成について、そのメリットや...
コンサル必見!リサーチレポートの作成を生成AIで効率化する方法
リサーチレポート作成は、膨大な情報を収集・分析し、まとめ上げる骨の折れる仕事です。生成AIを使えば、人間の専門知識や洞察力を組み合わせることで、より効率的で質の高いリサーチレポートを作成できます。本記事では、コンサルがリサーチレポート作成に...
生成AIで取扱説明書の作成を効率化!手順とメリット、注意点とは?
「取扱説明書の作成に時間がかかりすぎる」「マニュアルの内容にばらつきがある」というお悩みはありませんか?生成AIを活用することで、取扱説明書の作成時間を大幅に短縮し、内容の質の向上と均一化を図ることができます。ただし、情報の正確性や著作権の...
生成AI/chatGPTを用いて競合調査/市場調査を効率化する方法
競合調査や市場調査は、ビジネス戦略を立てる上で不可欠な作業です。しかし、膨大な情報を収集し、分析するのは時間と労力のかかる作業。そんな中、生成AIやChatGPTの登場により、この調査プロセスを大幅に効率化できる可能性が生まれました。本記事...
生成AIで求人原稿の作成を効率化|具体的な方法について
「求人原稿の作成に時間がかかりすぎる」「魅力的な求人原稿を書くのが難しい」など、求人原稿の作成は多くの企業にとって時間と労力を要する作業です。この作業で生成AIを使うことで、採用活動の効率化、業務負担の軽減、求人情報のクオリティ向上が実現で...
研修教材作成に生成AIを導入するメリット・注意点とは?
「研修教材の作成に時間がかかりすぎる」「効果的な教材を作るのが難しい」など、研修教材の作成は時間と労力がかかり、かつ効果的な内容を盛り込むのは容易ではありません。生成AIを活用した研修教材作成であれば、AIの提案を基に人間が内容を調整するこ...
生成AIで提案書/営業資料を作成する方法【Dify活用編】
ビジネスの世界で、提案書や営業資料の作成は欠かせない重要な業務です。しかし、多くの場合、この作業には相当な時間と労力が必要となります。締め切りに追われ、内容の充実よりも完成を急ぐことも少なくありません。本記事では、生成AIを活用した提案書/...
人気記事ランキング
おすすめ記事
