









この記事に関連するお役立ち資料

AIを活用した業務自動化 事例BOOK
無料ダウンロード
ビッグデータとAI技術の急速な進歩により、企業は膨大な高次元データを効率的に処理し、有益な洞察を得ることが求められています。しかし、従来のデータベースでは、複雑な構造を持つ大量のデータを扱うことが困難になってきました。
このような状況の中で、多くの企業が新しいデータ管理の手法として選びたいのがベクトルデータベースです。
本記事では、ベクトルデータベースの基本概念から活用事例、さらには将来の展望まで包括的に解説します。
AIと高度なデータ分析の導入をサポートする専門家に相談してみませんか?

- ベクトルデータベースとは
- 従来のデータベースとベクトルデータベースの違い
- ベクトルデータベースの特徴は3つ
- 高次元データの効率的な処理
- 類似性の高いデータの検索
- 機械学習への応用
- ベクトルデータベースを使う5つのメリット
- 検索・分析の高速化
- 類似性の高いデータの発見
- 機械学習への応用
- データ分析の高度化
- スケーラビリティの向上
- ベクトルデータベースの3つのデメリット
- 従来のデータベースと互換性がない
- データの前処理が複雑になる
- 精度と速度がトレードオフとなる
- ベクトルデータベースの活用事例
- 画像検索
- レコメンデーションシステム
- 自然言語処理
- 不正検知
- ベクトルデータベースの今後の展望
- まとめ
- よくある質問(FAQ)
- ベクトルデータベースとグラフデータベースの違いは何ですか?
- ベクトルデータベースとリレーショナルデータベースの違いは何ですか?
- ベクトルデータの例は?
- ベクトルデータの弱点は何ですか?
- ベクトルデータベースの次元の呪いとは?
- ラストデータとベクトルデータの違いは何ですか?
- ビットマップデータとベクトルデータの違いは何ですか?
ベクトルデータベースとは
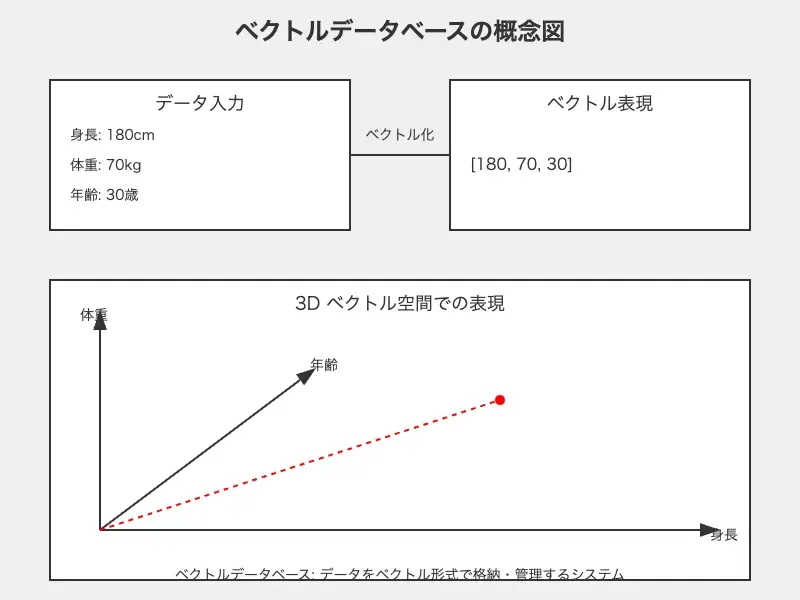
ベクトルデータベースとは、データをベクトル形式で格納・管理するデータベースシステムのことです。ここでいうベクトルとは、大きさ(長さや強さ)と方向を同時に表現する数値の配列のことを指します。
数値は、矢印や座標系での数値の組(例:(x, y, z))となっており、例では3つの異なる属性を1つの構造として保存しています。
例:
身長180cm、体重70kg、年齢30歳
[180, 70, 30]
このアプローチの核心は、このようにデータの特徴をベクトルとして捉え、すべての属性が数値で表現されて計算や比較が容易なことです。また、膨大なデータの中から高速に類似データを見つけ出すことも可能です。
従来のデータベースとベクトルデータベースの違い
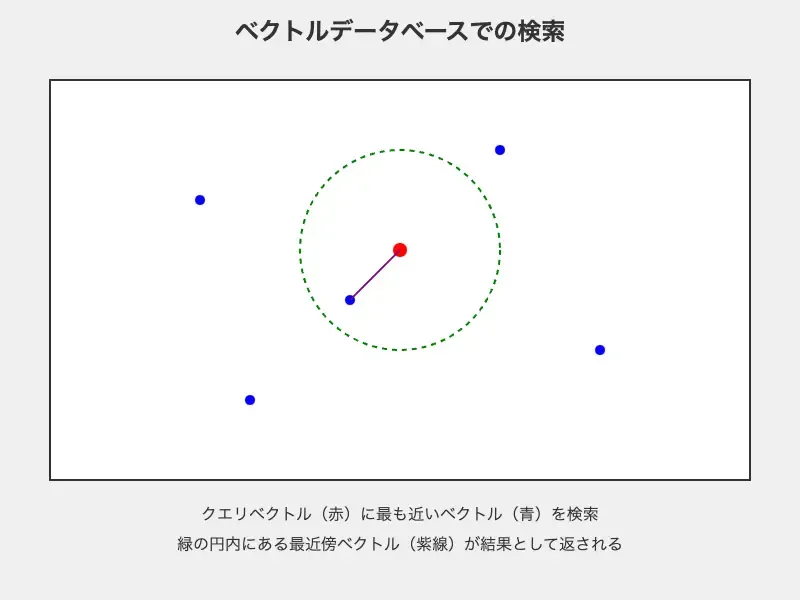
ベクトルデータベースの基盤は、データベースシステムです。大量の情報を構造化し、複数のユーザーが同時にアクセスして必要なデータを迅速に取得できることが特徴です。
一方で、従来のデータベースはクエリのマッチ度で抽出するものでした。
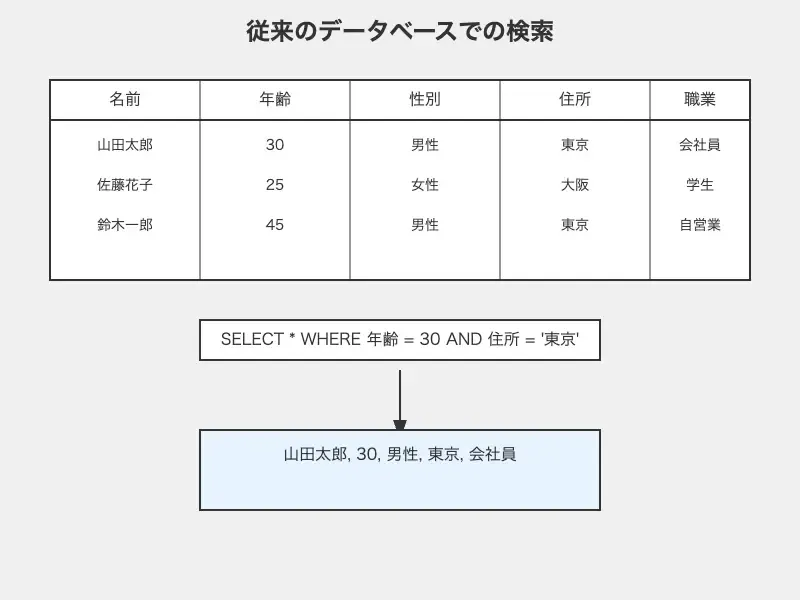
このお従来のデータベースとベクトルデータベースの主な違いは、データの格納方法と検索アプローチにあります。以下に、違いを詳しく見ていきましょう。
項目 | 従来のデータベース | ベクトルデータベース |
|---|---|---|
データの格納方法 | 構造化されたテーブル形式でデータを管理。例:顧客情報を「名前」「年齢」「住所」などの列に分けて格納 | データをベクトル(数値の配列)として格納。 |
高次元データの扱い | 高次元データの関係性を表現するのが困難。 | 高次元データの意味とコンテキストをベクトルで自然に表現。複雑なデータ構造も効率的に管理可能 |
検索方法 | 主に完全一致や部分一致などのキーワード検索。「東京に住む30歳の男性」のような条件検索が得意 | ベクトル間の類似度に基づいて検索。「この画像に似ている画像を探す」といった意味やコンテキストに基づいた検索が可能 |
検索速度と精度 | 構造化データの検索は高速だが、非構造化データ(テキストや画像など)の意味的な検索は困難 | 近似最近傍アルゴリズムを使用し、大量のデータから高速に類似データを見つけ出せる。非構造化データの意味的な検索も可能 |
スケーラビリティ | データ量が増えると複雑なクエリの実行時間が増加する傾向にある | データ量が増えても検索速度の低下を最小限に抑えられるよう設計されている |
もっとわかりやすく比較するなら、以下のとおりです。
〇:得意・適している、△:部分的に対応・やや苦手、×:苦手・非対応
項目 | 従来のDB | ベクトルDB |
|---|---|---|
構造化データの扱い | 〇 | 〇 |
非構造化データの扱い | △ | 〇 |
高次元データの効率的管理 | × | 〇 |
キーワード検索 | 〇 | △ |
意味的検索 | × | 〇 |
大規模データでの検索速度 | △ | 〇 |
完全一致検索 | 〇 | △ |
類似度検索 | × | 〇 |
スケーラビリティ | △ | 〇 |
このように、ベクトルデータベースは従来のデータベースとは異なるアプローチでデータを管理し、特に高次元データや非構造化データの処理に強みを発揮し、AIや機械学習の分野で重要な役割を果たすようになっています。
では、主な特徴とは具体的に何でしょうか?次で詳しくお伝えします。
ベクトルデータベースの特徴は3つ

ベクトルデータベースの主要な特徴は、以下の3つに集約されます。
高次元データの効率的な処理
類似性の高いデータの検索
機械学習への応用
高次元データの効率的な処理
ベクトルデータベースの強みは、高次元データを効率的に処理できることです。従来のキーワード検索では難しかった、意味やコンテキストに基づいた検索を「ベクトルという数値」で可能にするためです。
例えば、範囲検索であれば、範囲内にある全てのベクトルを検索できます。
クエリが "175から185cmの身長で、65から75kgの体重、30代の人"だとするなら、システムは[175-185, 65-75, 30-39]の結果を返すのです。
従来のデータベースでは、このような高次元データを効率的に扱うことは困難でしたが、ベクトルデータベースでは自然に扱えます。そのため、画像認識、自然言語処理、推薦システムなど、多様な分野で活用されています。
類似性の高いデータの検索
ベクトルデータベースのもう1つの重要な特徴は、データ間の類似性に基づいて検索を行える点です。従来のキーワード検索では発見できなかったような、意味的に関連性の高いデータを見つけることが可能です。
先に挙げた身長・体重・年齢のデータで、 [178, 72, 31]というクエリで検索すると、 [180, 70, 30] の人を候補として挙げるという具合です。完全一致でなくても、近い特徴を持つ人物を検索できます。
他にも、ベクトル間の距離(コサイン類似度やユークリッド距離など)を計算することで、類似度の高いデータを効率的に抽出します。
タイプ | 検索 | 結果 |
|---|---|---|
テキスト検索 | 「犬」というキーワードで検索 | 「イヌ」「わんこ」「ペット」など、意味的に関連する単語を含む |
画像検索 | 特定の画像に類似した画像を検索 | 色彩や形状などの特徴に基づいて類似した画像を見つける |
商品推薦 | ユーザーの購買履歴や閲覧履歴をベクトル化して検索 | 類似度の高い他のユーザーが購入した商品を推薦 |
このような類似性検索は、従来のデータベースでは実現が難しかった機能です。ベクトルデータベースによって、より直感的で柔軟な検索が可能になりました。
機械学習への応用
ベクトルデータベースは、機械学習のアルゴリズムと高い親和性を持っています。機械学習モデルの学習や評価、さらにはモデルの結果を活用したアプリケーションの開発がしやすくなります。
例えば、以下のようなイメージです。
No. | 項目 | 説明 |
|---|---|---|
1 | モデルの学習データ管理 | ベクトル形式で学習データを管理し、類似データを抽出 |
2 | 特徴抽出 | 機械学習モデルの特徴をベクトルとして保存 |
3 | 推論の高速化 | 学習済みモデルの重みをベクトルとして保存し、リアルタイム予測 |
4 | 異常検知 | 正常データのパターンを学習し、異常を検出 |
5 | 転移学習 | 学習した特徴ベクトルを別のタスクに転用 |
このように、ベクトルデータベースは機械学習のワークフロー全体を支援し、AIアプリケーションの開発と運用を効率化します。
では、実際の運用において、どのようなメリットとデメリットがあるのでしょうか?次で、具体的に見ていきましょう。
システム開発やAI活用を想定されている方に役立つ情報を発信中!

ベクトルデータベースを使う5つのメリット

まず、ベクトルデータベースを使うメリットには、以下の5つが挙げられます。
検索・分析の高速化
類似性の高いデータの発見
機械学習への応用
データ分析の高度化
スケーラビリティの向上
検索・分析の高速化
ベクトルデータベースは、高次元データの効率的な処理により、大規模データセットでも高速な検索と分析が可能です。近似最近傍アルゴリズムを使用することで、類似度の高いデータを見つけ出せます。
類似性の高いデータの発見
また、ベクトル間の距離計算により、意味的に関連性の高いデータを容易に発見できます。キーワード検索では見つけられない、潜在的な関連性を持つデータを抽出できるのが強みです。
機械学習への応用
ベクトルデータベースであれば、機械学習モデルとの高い親和性により、学習データの管理や特徴抽出がしやすくなります。モデルの学習結果をベクトルとして保存し、推論の高速化や転移学習に活用するなどです。
関連記事:転移学習とは?ファインチューニングやRAGとの違い・注意点をわかりやすく解説
データ分析の高度化
通常のデータベースでは扱いきれないような複雑なデータ構造を、単純なベクトル表現に変換することでより深い洞察を得られます。非構造化データ(テキスト、画像、音声など)の意味的な分析も可能です。
スケーラビリティの向上
最後に、ベクトルデータベースはデータ量が増加しても、検索速度の低下を最小限に抑えられるよう設計されています。分散システムとの親和性が高く、大規模なデータ処理にも適しています。
とはいえ、メリットばかりだけではなく、しっかりとデメリットも存在します。
ベクトルデータベースの3つのデメリット

高次元データの効率的な処理能力を有する一方で、ベクトルデータベースには以下のデメリットがあります。
従来のデータベースと互換性がない
データの前処理が複雑になる
精度と速度がトレードオフとなる
また、構築には専門性を求められ、一定のコストがかかることにも留意してください。
従来のデータベースと互換性がない
ベクトルデータベースは、既存のリレーショナルデータベースとの直接的な互換性がないため、システム移行に時間とコストがかかります。専用のハードウェアやソフトウェアが必要な場合、初期投資も高くなるといった具合です。
SQLなどの標準的なクエリ言語が使用できず、新しいクエリ方法を学ぶ必要もあります。加えて、運用やメンテナンスに専門的なスキルを持つ人材が必要となり、人件費が増加することも想定してください。
データの前処理が複雑になる
ベクトルデータベースでは、生データをベクトル形式に変換する前処理が必要であり、この過程で情報の損失や歪みが生じます。ベクトル表現やベクトル検索アルゴリズムに関する専門知識を有した人材が必要です。
また、適切なベクトル表現を選択するには、試行錯誤が必要なことも少なくありません。
精度と速度がトレードオフとなる
最後に、近似最近傍アルゴリズムを使用する場合、検索速度と精度のバランスを取る必要があります。完全に正確な結果を得るには、高い計算コストを求められるかもしれません。
ベクトルデータベースの課題解決には専門知識が必要です。効率的な運用方法や最適な活用方法について、経験豊富な専門家に相談してみませんか?

ベクトルデータベースのメリットとデメリットを理解したところで、具体的にどのような分野で活用されているのでしょうか?実際の活用事例を見てみましょう。
ベクトルデータベースの活用事例

ベクトルデータベースの活用事例には、以下のようなものがあります。
画像検索
レコメンデーションシステム
自然言語処理
不正検知
画像検索
画像検索は、ベクトルデータベースの特性を最大限に活かせる分野の1つです。商品画像の類似検索や人物画像の顔認証などに広く活用されています。
画像をベクトル化することで、色彩、形状、テクスチャなどの特徴を数値として表現し、高速かつ高精度な類似画像を検索できます。従来のキーワード検索では難しかった、視覚的な類似性に基づく検索を実現できるのです。
レコメンデーションシステム
レコメンデーションシステムは、ユーザーの過去の行動履歴に基づいて、おすすめの商品やサービスを推薦するシステムです。各データをベクトル化し、より精度の高いパーソナライズしたレコメンデーションを以下のように展開できます。
サービス | ベクトル化による推薦 |
|---|---|
ECサイト | 購買履歴から類似商品を推薦 |
動画配信 | 視聴履歴から類似コンテンツを推薦 |
音楽配信 | 聴取履歴から類似楽曲を推薦 |
ベクトルデータベースを用いたレコメンデーションシステムは、ユーザー体験の向上と、それに伴う顧客満足度の向上、さらには売上の増加にも貢献します。
自然言語処理
自然言語処理の分野では、ベクトルデータベースが文章の類似性や意味の解析、RAG(Retrieval Augmented Generation)などに活用されています。
応用分野 | 説明 |
|---|---|
テキスト分類・感情分析 | ベクトル化で意味や感情を数値化。高速・高精度な分析。 |
質問応答システム | 質問と回答候補をベクトル化。最も類似度の高い回答を選択。 |
最近注目を集めているRAGでは、大規模言語モデルの生成能力と、ベクトルデータベースの検索能力を組み合わせることで、より正確で最新の情報に基づいた回答を生成できます。
詳しくは、下記ページもご覧ください。
関連記事:
不正検知
不正検知の分野では、ベクトルデータベースが不正な取引や詐欺行為の検知に活用されています。
ユーザーの過去の取引履歴や、同様の属性を持つユーザーの取引パターンをベクトル化し、新しい取引がこのパターンから大きく逸脱している場合に、不正のことが多いと判断するなどです。
ベクトルデータベースを活用した不正検知システムは、従来の規則ベースのシステムでは検出が困難だった複雑な不正パターンも発見でき、企業のリスク管理と顧客保護に大きく貢献します。
ベクトルデータベースの活用事例を見てきましたが、この技術の未来はどのように発展していくのでしょうか?今後の展望を探ってみましょう。
ベクトルデータベースの今後の展望

ベクトルデータベースは、AI技術の進化と共に急速に発展しており、今後さらなる利活用が期待されています。以下のような精度や連携性などは、発展するとより便利かつ豊かになるはずです。
検索・分析の精度向上
従来のデータベースと連携
コスト削減と運用の簡易化
新たな応用分野の開拓
プライバシーとセキュリティの強化
エッジコンピューティングとの融合
ベクトルデータベースは、データ駆動型の意思決定や AI アプリケーションの基盤技術として、今後ますます重要性を増していくでしょう。技術の進化と共に、より多くの企業がベクトルデータベースを採用し、データの価値を最大限に引き出すことも期待されます。
まとめ

ベクトルデータベースは、高次元データの効率的な処理、類似性の高いデータの検索、機械学習への応用という特徴を持つ技術です。
画像検索、レコメンデーションシステム、自然言語処理、不正検知など、幅広い分野での活用が進んでおり、ビジネスの効率化や顧客体験の向上に大きく貢献しています。一方で、専門知識の必要性やコスト面での課題もあり、導入にあたっては慎重な検討が必要です。
ベクトルデータベースの課題解決には専門知識が必要です。効率的な活用方法や最適な実装について、経験豊富な専門家に相談してみませんか?

よくある質問(FAQ)
ベクトルデータベースとグラフデータベースの違いは何ですか?
ベクトルデータベースとグラフデータベースは、異なる目的と構造を持つデータベースです。
ベクトルデータベースは、データを数値の配列(ベクトル)として表現し、類似性検索に特化しています。一方、グラフデータベースは、データをノードとエッジの関係として表現し、複雑な関係性の分析に適しています。
ベクトルデータベースとリレーショナルデータベースの違いは何ですか?
ベクトルデータベースとリレーショナルデータベースは、データの格納方法と検索方法が大きく異なるものです。
リレーショナルデータベースは、構造化されたテーブル形式でデータを管理し、主にキーワードや条件に基づく検索を行います。一方、ベクトルデータベースは、データをベクトル(数値の配列)として格納し、類似性に基づく検索を行います。
ベクトルデータの例は?
ベクトルデータの例には、以下のようなものがあります。
データタイプ | ベクトル表現 |
|---|---|
画像データ | 画像の色彩や形状などを数百次元のベクトルで表現 |
テキストデータ | 単語や文章の意味を数百次元のベクトルで表現(Word2Vec, BERT等) |
音声データ | 音声の特徴を周波数成分のベクトルで表現 |
ユーザー行動データ | 閲覧履歴や購買履歴を数値化してベクトル化 |
センサーデータ | IoTデバイスから得られる複数の測定値をベクトルとして表現 |
ベクトルデータの弱点は何ですか?
ベクトルデータの主な弱点には、以下のようなものがあります。
弱点 | 説明 |
|---|---|
解釈の難しさ | 高次元ベクトルの直感的理解が困難 |
次元の呪い | 次元増加で類似性判断が難しくなる |
データ損失 | ベクトル化で情報が失われる可能性 |
計算コスト | 処理に大きな計算リソースが必要 |
適切なベクトル選択 | 最適なベクトル化手法の選択が難しい |
ベクトルデータベースの次元の呪いとは?
ベクトルデータベースの「次元の呪い」とは、次元数が増えるとデータも疎になり、類似性判断や検索が難しくなる現象です。高次元空間では距離の意味が薄れ、計算コストも増大します。これに対しては、次元削減や効率的なアルゴリズムを用いて対処します。
ラストデータとベクトルデータの違いは何ですか?
ラストデータとベクトルデータは、データの構造と用途が異なります。
ラストデータ(Rust data)は、Rustプログラミング言語で使用されるデータ構造を指し、型安全性と並行性に優れています。一方、ベクトルデータは、数値の配列として表現されるデータ形式で、主に機械学習や類似性検索に使用されるものです。
ビットマップデータとベクトルデータの違いは何ですか?
ビットマップデータとベクトルデータは、主に画像データの表現方法として比較され、以下の違いがあります。
項目 | ビットマップ | ベクトルデータ |
|---|---|---|
構造 | ピクセルの格子で構成され、各ピクセルに色情報が割り当てられる | 数学的な式で形状や線を表現 |
拡大縮小 | 拡大すると画質が劣化する | 品質を保ったまま拡大縮小できる |
ファイルサイズ | 複雑な画像では小さくなる | 単純な図形ではコンパクト |
編集 | 個々のピクセルを編集できる | 形状や属性を容易に変更できる |
用途 | 写真などの複雑な画像に適している | ロゴやイラストに適している |

この記事に関連するお役立ち資料を無料ダウンロード
AIを活用した業務自動化 事例BOOK
AI技術を活用した社内業務効率化の基本から、実際の導入ステップまでをわかりやすく解説しています。
下記フォームにご記入下さい。(30秒)
テックユニットは、下記のような方におすすめできるサービスです。
お気軽にご相談ください。
・開発リソースの確保に困っている方
・企業の新規事業ご担当者様
・保守運用を移管したい方
・開発の引き継ぎを依頼したい方


おすすめの記事
関連する記事はこちら
生成AIを用いたアンケート分析:メリットと活用のコツ
アンケート分析は、顧客の声を理解し事業戦略を立てる上で欠かせません。しかし、従来の人手によるアンケート分析では、大量データの処理や複雑な分析に膨大な時間と労力が必要です。本記事では、これらの課題を解決する生成AIとChatGPTを活用したア...
生成AIで顧客分析・顧客フィードバック分析を効率化!導入手順とメリットとは?
顧客の満足度向上と長期的な関係構築は、どの企業にとっても重要な目標です。これを実現するには、顧客のニーズを正確に把握する必要があります。しかし、従来の分析手法では、顧客分析に時間と労力がかかりすぎてしまいます。そこで注目を集めているのが、生...
【2024年最新】AI/生成AIのパーソナライズ事例と導入ステップを徹底解説
「生成AIを活用したいけど、どうすればパーソナライズできるのか分からない」「生成AIのパーソナライズ導入にはリスクがあるのではないか」というお悩みはありませんか?生成AIを用いたパーソナライズは、顧客体験の改善や業務プロセスの最適化など、多...
業務に使える文書作成の生成AIツール10選|活用例や注意点も解説
ビジネスの現場では文書を作成する機会が多く、「文書作成に時間がかかりすぎる」「クオリティの高い文章を効率的に作成したい」などの悩みは尽きません。しかし、一般的なAIライティングツールでは、ビジネスの現場で求められる高度な要求に応えきれないこ...
生成AIでRFP(提案依頼書)への回答を効率化!メリットと具体的な手順を解説
RFP(提案依頼書)の回答作成において、「時間がかかりすぎる」「ミスが心配」「もっと効率的に作成できないか」といった悩みを抱えている方も多いのではないでしょうか。RFPには一定の形式や構造があり、テンプレートで作成できることから、生成AIと...
生成AIによる報告書の自動作成|選定基準や導入効果、注意点について
報告書で作成に時間がかかり、ミスの心配も付きまとう…そのような悩みを抱えていませんか?生成AIを活用すれば、作成時間の大幅短縮やコスト削減、さらには品質の向上まで実現可能です。本記事では、AIを使った報告書の自動作成について、そのメリットや...
コンサル必見!リサーチレポートの作成を生成AIで効率化する方法
リサーチレポート作成は、膨大な情報を収集・分析し、まとめ上げる骨の折れる仕事です。生成AIを使えば、人間の専門知識や洞察力を組み合わせることで、より効率的で質の高いリサーチレポートを作成できます。本記事では、コンサルがリサーチレポート作成に...
生成AIで取扱説明書の作成を効率化!手順とメリット、注意点とは?
「取扱説明書の作成に時間がかかりすぎる」「マニュアルの内容にばらつきがある」というお悩みはありませんか?生成AIを活用することで、取扱説明書の作成時間を大幅に短縮し、内容の質の向上と均一化を図ることができます。ただし、情報の正確性や著作権の...
生成AI/chatGPTを用いて競合調査/市場調査を効率化する方法
競合調査や市場調査は、ビジネス戦略を立てる上で不可欠な作業です。しかし、膨大な情報を収集し、分析するのは時間と労力のかかる作業。そんな中、生成AIやChatGPTの登場により、この調査プロセスを大幅に効率化できる可能性が生まれました。本記事...
生成AIで求人原稿の作成を効率化|具体的な方法について
「求人原稿の作成に時間がかかりすぎる」「魅力的な求人原稿を書くのが難しい」など、求人原稿の作成は多くの企業にとって時間と労力を要する作業です。この作業で生成AIを使うことで、採用活動の効率化、業務負担の軽減、求人情報のクオリティ向上が実現で...
研修教材作成に生成AIを導入するメリット・注意点とは?
「研修教材の作成に時間がかかりすぎる」「効果的な教材を作るのが難しい」など、研修教材の作成は時間と労力がかかり、かつ効果的な内容を盛り込むのは容易ではありません。生成AIを活用した研修教材作成であれば、AIの提案を基に人間が内容を調整するこ...
生成AIで提案書/営業資料を作成する方法【Dify活用編】
ビジネスの世界で、提案書や営業資料の作成は欠かせない重要な業務です。しかし、多くの場合、この作業には相当な時間と労力が必要となります。締め切りに追われ、内容の充実よりも完成を急ぐことも少なくありません。本記事では、生成AIを活用した提案書/...
人気記事ランキング
おすすめ記事
